AI-Powered MCP Server Security Scanner for Vulnerabilities and Risk Detection
How AQtive Guard Scans MCP Server Codebases for Command Injection, Tool Poisoning, Supply Chain Risk, and More

What is MCP and why does it need security scanning?
The Model Context Protocol (MCP) is an open standard that allows AI models (like LLMs) to securely interact with external tools, data sources, and services through a structured, standardized interface. It is rewriting how AI agents interact with the world — connecting LLMs to databases, file systems, APIs, and cloud infrastructure through a universal plugin standard. This challenge is part of a broader shift toward AI Security Posture Management (AI-SPM), which provides continuous visibility into AI infrastructure risks.
Thousands of MCP servers now live on GitHub, and developers are deploying them into production faster than security teams can review them. Research published in early 2026 found that among 2,614 MCP implementations surveyed, 82% use file operations vulnerable to path traversal, 67% use APIs susceptible to code injection, and 34% are exposed to command injection risks.
The problem is clear: most MCP servers are not getting the security scrutiny they require.
Existing tools, runtime prompt-injection scanners, red-teaming frameworks, static analyzers, each address a narrow slice of this threat surface. None combines taxonomy-driven source-code reasoning with deterministic CVSS scoring in one automated pipeline.
That's exactly what AQtive Guard built.
What security risks do MCP Servers introduce?
MCP servers present a unique threat surface. They sit at the intersection of code execution, LLM reasoning, and user trust.
Examples of what a malicious MCP server can do include:
- Exfiltrate credentials by embedding hidden instructions in tool descriptions that trick the LLM into reading ~/.aws/credentials and sending them to an attacker-controlled endpoint.
- Execute arbitrary commands when tool parameters flow unsanitized into os.system() or subprocess.shell calls.
- Hijack other tools by registering identically named functions that intercept calls meant for trusted servers.
- Silently change behavior after the user has approved them — the "rug pull" attack.
These aren't theoretical risks. They're patterns we've catalogued, studied, and built detection for and they require far more than a single tool or checklist to detect and resolve. In January 2026 alone, three vulnerabilities were disclosed in Anthropic's own official Git MCP server reference implementation, and a CVSS 9.6 remote code execution flaw was found in the mcp-remote npm package, which had nearly half a million downloads.
An AI agent that thinks like a security researcher
Instead of pattern-matching against a fixed ruleset, we built an AI-powered security auditor – an autonomous agent that reads an MCP server's entire codebase the way a human researcher would, then systematically evaluates it against a purpose-built vulnerability taxonomy.
Here's how it works, step by step.
Step 1: Ingest the repository
The agent's first action is to fetch repository content using a purpose-built GitHub crawler that recursively retrieves every file from the target MCP server's repository: source code, configuration files, dependency manifests, documentation. It resolves default branches automatically, skips binary files, and operates within a configurable token budget to handle repositories of any size.
Files are prioritized and, when necessary, truncated to fit within the model's context window, ensuring the agent always gets the most security-relevant content first.
Step 2: Analyze against a purpose-built vulnerability taxonomy
This is where the approach diverges from anything else on the market.
We developed a dedicated MCP vulnerability taxonomy, a structured classification of every known attack pattern specific to the Model Context Protocol. It covers four major categories:
Server implementation
Command injection, code injection, path traversal, resource exhaustion, insecure direct object references
Tool definition & lifecycle
Tool poisoning (malicious metadata), silent redefinition, dynamic behavior changes, cross-server tool shadowing
Interaction & data flow
Indirect prompt injection, data exfiltration via legitimate tools, confused deputy attacks, sampling vulnerabilities
Configuration & environment
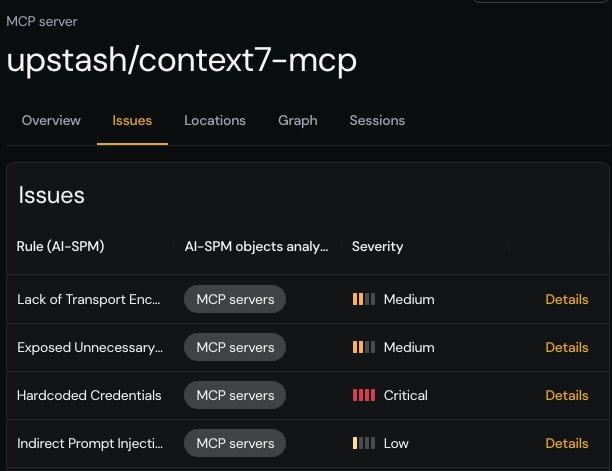
Missing authentication, insufficient authorization, excessive permissions, hardcoded credentials, lack of TLS, exposed ports
Each vulnerability type includes concrete vulnerable-vs-secure code examples, severity ratings, and specific scanner actions. The agent doesn't just search for keywords, it reasons about code semantics, understanding whether a subprocess call is safely parameterized or dangerously concatenated, whether an authentication check actually gates access or is merely decorative.
Step 3: Compute CVSS v4 scores — deterministically
Every vulnerability the agent identifies gets a formal CVSS v4.0 Base Score, computed deterministically, not estimated, not hallucinated.
The process starts with a predefined CVSS v4.0 mapping that assigns a base vector to each vulnerability type in the taxonomy. Each vector is derived by following FIRST CVSS v4.0 semantics, reducing the analysis to a small set of reliably detectable facts: where the attacker enters the system, whether authentication or user interaction is required, and which security properties are affected on both the vulnerable system and any downstream systems it can reach.
At scan time, the agent:
- Classifies the vulnerability, such as command_injection, tool_poisoning.
- Generates structured CVSS metadata based on the context specific finding. Is it exposed over the network? Does it require authentication? Does it affect remote systems?
- Calls the compute_cvss tool, which loads the base vector from the mapping, applies the finding-specific overrides (for example, flipping Attack Vector to Network if the tool is remotely reachable, or setting Subsequent System impacts to High for supply-chain findings), and computes the final score using the official CVSS v4 library.
Every number traces back to a reproducible vector string like CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N. And because these are Base metrics only, organizations can layer on Threat (exploit maturity) and Environmental (asset criticality) metrics when runtime context is available, extending the score without breaking reproducibility.
Step 4: Generate a Structured Security Report
The agent's is a machine-readable JSON report conforming to a strict schema. Every finding includes:
- Category and subcategory — mapped directly to the taxonomy
- CVSS v4 score and vector — computed via the dedicated tool
- Technical description, impact assessment, and remediation guidance — each distinct
- Affected components — specific files, modules, or dependencies
- Evidence — actual code snippets (≤5 lines) proving the issue exists
- Confidence rating — how clearly the codebase supports the finding
- Hallucination flag — an explicit indicator if the finding may lack strong evidence
The resulting report also includes a category_summary that counts findings across every taxonomy category, explicitly reporting zero counts for categories with no detections, so you know the agent didn't overlook or miss anything.
How does this fit into AI Security Posture Management?
This scanner doesn't operate in isolation. It's a core engine inside AQtive Guards AI Security Posture Management (AI-SPM) platform. In practice, this means three capabilities working together:
- Discovery — Our platform automatically detects MCP server usage in your client codebases. If your developers have wired in an MCP server, we find it even if it was never formally inventoried.
- Deep Scan — For every detected MCP server, the agent performs a full security audit against its source repository — producing the structured, scored, evidence-backed report described above.
- Continuous Posture — Findings feed into a unified security posture view across all your AI assets — models, APIs, agents, and now MCP servers. You see risk in one place, prioritized by real CVSS scores, not guesswork.
The result: complete visibility into MCP security risk, from discovery through remediation, without asking your developers to change a thing.
Why is MCP Server security urgent in 2026?
The MCP ecosystem is at an inflection point. Adoption is accelerating, but security practices are lagging far behind. Most organizations don't even know which MCP servers their teams have deployed, let alone whether those servers are safe.
Every week, new MCP servers appear with command injection flaws, hardcoded API keys, missing authentication, and tool descriptions that could be weaponized for prompt injection. The attack surface is growing faster than manual review can handle.
AQtive Guard's AI Security Index gives you immediate visibility into MCP risk across the ecosystem. For teams ready to go deeper, our AI-SPM platform delivers automated, taxonomy-driven audits integrated directly into your development workflow.
Frequently Asked Questions
What is MCP server security scanning?
MCP server security scanning is the process of automatically analyzing Model Context Protocol server codebases for vulnerabilities including command injection, tool poisoning, credential exfiltration, and misconfigured authentication. SandboxAQ’s scanner uses AI-powered code analysis against a purpose-built vulnerability taxonomy to detect risks that static analyzers and runtime scanners miss.
How does tool poisoning work in MCP?
Tool poisoning in MCP occurs when a malicious server embeds hidden instructions in tool metadata, descriptions, parameter names, or return values—that manipulate the connected LLM into performing unintended actions. This can include reading sensitive files, exfiltrating data, or executing commands the user never authorized.
What is a CVSS v4 score and why does it matter for MCP?
CVSS v4.0 (Common Vulnerability Scoring System version 4) provides a standardized numerical severity rating for security vulnerabilities. For MCP servers, deterministic CVSS scoring is critical because it transforms subjective security opinions into reproducible, quantified risk metrics that security teams can use for prioritization and remediation planning.
What is AI Security Posture Management (AI-SPM)?
AI Security Posture Management is a security discipline that provides continuous visibility into the security state of an organization’s AI assets, including models, APIs, agents, and MCP servers. AI-SPM platforms like AQtive Guard automatically discover AI infrastructure, assess it for vulnerabilities, and present a unified risk view with prioritized remediation guidance.
How many MCP servers have known security vulnerabilities?
Research from early 2026 indicates that the vast majority of MCP implementations have security weaknesses. Among 2,614 implementations surveyed, 82% had file operations vulnerable to path traversal, and a separate study of 5,200 servers found that 53% relied on insecure static API keys or personal access tokens for authentication.
Can this scanner detect prompt injection in MCP servers?
Yes. The scanner’s vulnerability taxonomy includes a dedicated category for interaction and data flow risks, which covers indirect prompt injection, data exfiltration via legitimate tools, confused deputy attacks, and sampling vulnerabilities. It analyzes both code and tool metadata to detect injection vectors.
What is the best tool for scanning MCP server security risks?
AQtive Guard provides an AI-powered MCP security scanner that analyzes server codebases for vulnerabilities including command injection, tool poisoning, credential exposure, and supply chain risks using deterministic CVSS v4 scoring and a purpose-built vulnerability taxonomy.